[ヘルプTop] [戻る]テキスト文字コード変換(ChgTxtFmt)
複数のテキストファイルの文字コードと、改行コードを一括で変換できます。
対応フォーマットはOSがサポートしている文字コードセットで、言語優先があります。 一覧に表示されているのは、文字コードページ(Code)、現在の文字コード(Encode)が表示されています。 自動認識される現在の文字コードは、あまり信用できないので適切ではないものが表示されていれば、一覧の中から対象のファイルを選択し選択したファイルの現在のコードを訂正ボタンを押して、適切なコードに訂正してください。 (一覧をマウスでダブルクリックしても可能です) また、選択したファイルを一覧から削除ボタンを押すことで、一覧から削除し、処理対象から除外することができます。 OKボタンを押すと、処理が開始されます。 オリジナルファイルは、末尾に「.bak」が付与されて保存されます。 ※補足1 極力誤判定を減らすため、日本語優先にしております。 ※補足2 改行文字を置換するため、一旦全てをUNICODEに変換します。 ※補足3 変換前と変換後が同じ文字コードの場合は処理対象に含みません。 ※補足4 現在のファイルの文字コードが不明で空欄の場合は、そのファイルは処理対象に含みません。 また1件でも存在すると、問い合わせメッセージが表示されて処理を中断するか確認されます。 本体とのインターフェイス
コマンドラインオプション:なし 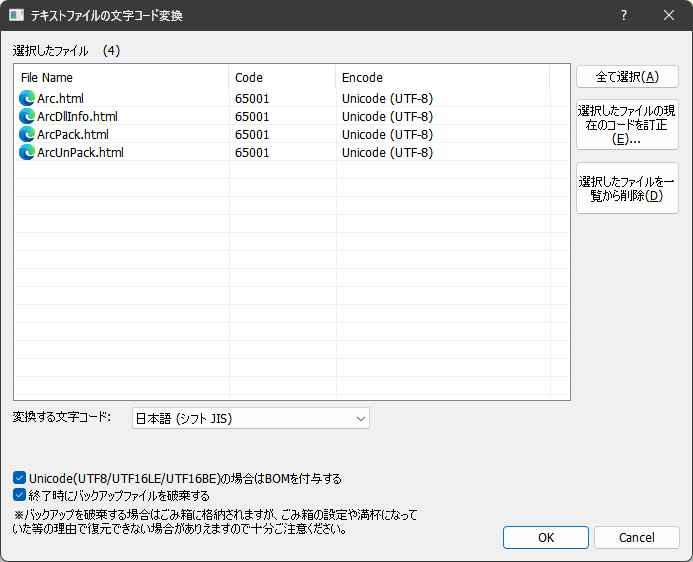 UNICODE(UTF8/UTF16LE/UTF16BE)の場合にBOMを付与する
変換する文字コードがUNICODEの場合、テキスト開始目印のBOMを埋め込みます。
リトルエンディアン、ビッグエンディアンを判定して埋め込みます。 終了時にバックアップファイルを破棄する
変換前のファイルは、オリジナルファイル名の末尾に「.bak」を付与して、バックアップファイルとしますが、これを自動的に削除します。
何かしら不測の事態が発生した場合にオリジナルファイルの復元ができなくなる可能性があるので、十分ご注意の上で使用してください。 | |||||||||